基于Unet+opencv实现天空对象的分割、替换和美化 |
您所在的位置:网站首页 › opencv inv › 基于Unet+opencv实现天空对象的分割、替换和美化 |
基于Unet+opencv实现天空对象的分割、替换和美化
|
传统图像处理算法进行“天空分割”存在精度问题且调参复杂,无法很好地应对云雾、阴霾等情况;本篇文章分享的“基于Unet+opencv实现天空对象的分割、替换和美化”,较好地解决了该问题,包括以下内容: 1、基于Unet语义分割的基本原理、环境构建、参数调节等 2、一种有效的天空分割数据集准备方法,并且获得数据集 3、基于OpenCV的Pytorch模型部署方法 4、融合效果极好的 SeamlessClone 技术 5、饱和度调整、颜色域等基础图像处理知识和编码技术本文适合具备 OpenCV 和Pytorch相关基础,对“天空替换”感兴趣的人士。学完本文,可以获得基于Pytorch和OpenCV进行语义分割、解决实际问题的具体方法,提高环境构建、数据集准备、参数调节和运行部署等方面综合能力。 一、传统方法和语义分割基础 1.1传统方法主要通过“颜色域”来进行分割 比如,我们要找的是蓝天,那么在HSV域,就可以通过查表的方法找出蓝色区域。  在这张表中,蓝色的HSV的上下门限已经标注出来,我们编码实现。 cvtColor(matSrc,temp,COLOR_BGR2HSV); split(temp,planes); equalizeHist(planes[2],planes[2]);//对v通道进行equalizeHist merge(planes,temp); inRange(temp,Scalar(100,43,46),Scalar(124,255,255),temp); erode(temp,temp,Mat());//形态学变换,填补内部空洞 dilate(temp,temp,Mat()); imshow("原始图",matSrc);在这段代码中,有两个小技巧,一个是对模板(MASK)进行了形态学变化,这个不展开说;一个是我们首先对HSV图进行了3通道分解,并且直方图增强V通道,而后将3通道合并回去。通过这种方法能够增强原图对比度,让蓝天更蓝、青山更青……大家可以自己调试看一下。 显示处理后识别为天空的结果(在OpenCV中,白色代表1也就是由数据,黑色代表0也就是没数据) 对于天坛这幅图来说,效果不错。虽然在右上角错误,而塔中间的一个很小的空洞,这些后期都是可以规避掉的错误。  但是对于阴霾图片来说,由于天空中没有蓝色,识别起来就很错误很多。  1.2 语义分割基础 图像语义分割(semantic segmentation),从字面意思上理解就是让计算机根据图像的语义来进行分割,例如让计算机在输入下面左图的情况下,能够输出右图。语义在语音识别中指的是语音的意思,在图像领域,语义指的是图像的内容,对图片意思的理解,比如左图的语义就是三个人骑着三辆自行车;分割的意思是从像素的角度分割出图片中的不同对象,对原图中的每个像素都进行标注,比如右图中粉红色代表人,绿色代表自行车。  那么对于天空分割问题来说,主要目标就是找到像素级别的天空对象,使用语义分割模型就是有效的。 二、Unet基本情况和环境构建 Unet 发表于 2015 年,属于 FCN 的一种变体,Unet 的初衷是为了解决生物医学图像方面的问题,由于效果确实很好后来也被广泛的应用在语义分割的各个方向,比如卫星图像分割,工业瑕疵检测等。它也有很多变体,但是对于天空分割问题来看,Unet的能力已经够了。 Unet 跟 FCN 都是 Encoder-Decoder 结构,结构简单但很有效。Encoder 负责特征提取,你可以将自己熟悉的各种特征提取网络放在这个位置。由于在医学方面,样本收集较为困难,作者为了解决这个问题,应用了图像增强的方法,在数据集有限的情况下获得了不错的精度。  如上图,Unet 网络结构是对称的,形似英文字母 U 所以被称为 Unet。整张图都是由蓝/白色框与各种颜色的箭头组成,其中,蓝/白色框表示 feature map;蓝色箭头表示 3x3 卷积,用于特征提取;灰色箭头表示 skip-connection,用于特征融合;红色箭头表示池化 pooling,用于降低维度;绿色箭头表示上采样 upsample,用于恢复维度;青色箭头表示 1x1 卷积,用于输出结果。 在环境构建这块,我建议一定要结合自己的实际情况,构建专用的代码库,这样才能够通过不断迭代,在总体正确的前提下形成自己风格。 在我的库中,基于现有的Unet代码进行了修改 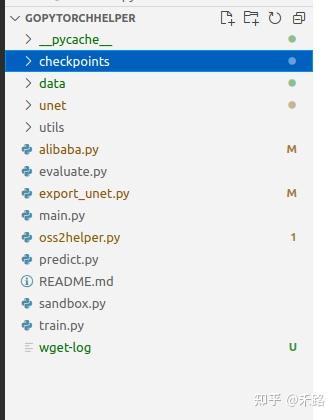 其中checkpoints、data保持数据;unet是模型的具体实现,未来可以扩充为多模型;utils是常用函数;alibaba.py和oss2helper.py是阿里云的辅助函数;export_unet.py是输出函数;eveluate.py和train.py用于训练;predict.py用于本地测试;main.py是主要函数。 三、数据集准备和增强 3.1 数据集准备这块,我采取了增强的方法。由于个人习惯问题,采用的是OpenCV本地变换的方法 getFiles("e:/template/Data_sky/data", fileNames); string saveFile = "e:/template/Data_sky/dataEX3/"; for (int index = 0; index < fileNames.size(); index++) { Mat src = imread(fileNames[index]); Mat dst; string fileName; getFileName(fileNames[index], fileName); resize(src, dst, cv::Size(512, 512)); imwrite(saveFile + fileName + "_512.jpg", dst); resize(src, dst, cv::Size(256, 256)); imwrite(saveFile + fileName + "_256.jpg", dst); resize(src, dst, cv::Size(128, 128)); imwrite(saveFile + fileName + "_128.jpg", dst); cout 0: if global_step % division_step == 0: histograms = {} for tag, value in net.named_parameters(): tag = tag.replace('/', '.') val_score = evaluate(net, val_loader, device) scheduler.step(val_score) logging.info('Validation Dice score: {}'.format(val_score)) if save_checkpoint: Path(dir_checkpoint).mkdir(parents=True, exist_ok=True) torch.save(net.state_dict(), str(dir_checkpoint / 'checkpoint_epoch{}.pth'.format(epoch + 1))) logging.info(f'Checkpoint {epoch + 1} saved!')4.2 推荐适当投资,采购了autodl进行在线训练  通过predict生成模板结果,在Photoshop中进行比对发现边界已经比较贴合,最终在增强的数据集上,实现了DICE90%的目标。  五、基于OpenCV的Pytorch模型部署方法 这里为了进行总结,我对分别对目前使用Python和C++下的几种可行可用的推断方法进行汇总,并进一步比对。 5.1 (python)使用onnxruntime方法进行推断 session = onnxruntime.InferenceSession("转换的onnx文件") input_name = session.get_inputs()[0].name label_name = session.get_outputs()[0].name img_name_list = ['需要处理的图片'] image = Image.open(img_name_list[0]) w, h = image.size dataset = SalObjDataset( img_name_list=img_name_list, lbl_name_list=[], transform=transforms.Compose([RescaleT(320), ToTensorLab(flag=0)]) ) data_loader = DataLoader( dataset, batch_size=1, shuffle=False, num_workers=1 ) im = list(data_loader)[0]['image'] inputs_test = im inputs_test = inputs_test.type(torch.FloatTensor) with torch.no_grad(): inputs_test = Variable(inputs_test) res = session.run([label_name], {input_name: inputs_test.numpy().astype(np.float32)}) result = torch.from_numpy(res[0]) pred = result[:, 0, :, :] pred = normPRED(pred) pred = pred.squeeze() predict_np = pred.cpu().data.numpy() im = Image.fromarray(predict_np * 255).convert('RGB') im = im.resize((w, h), resample=Image.BILINEAR) im.show()5.2 (python) 使用opencv方法 import os import argparse from skimage import io, transform import numpy as np from PIL import Image import cv2 as cv parser = argparse.ArgumentParser(description='Demo: U2Net Inference Using OpenCV') parser.add_argument('--input', '-i') parser.add_argument('--model', '-m', default='u2net_human_seg.onnx') args = parser.parse_args() def normPred(d): ma = np.amax(d) mi = np.amin(d) return (d - mi)/(ma - mi) def save_output(image_name, predict): img = cv.imread(image_name) h, w, _ = img.shape predict = np.squeeze(predict, axis=0) img_p = (predict * 255).astype(np.uint8) img_p = cv.resize(img_p, (w, h)) print('{}-result-opencv_dnn.png-------------------------------------'.format(image_name)) cv.imwrite('{}-result-opencv_dnn.png'.format(image_name), img_p) def main(): # load net net = cv.dnn.readNet('saved_models/sky_split.onnx') input_size = 320 # fixed # build blob using OpenCV img = cv.imread('test_imgs/sky1.jpg') blob = cv.dnn.blobFromImage(img, scalefactor=(1.0/255.0), size=(input_size, input_size), swapRB=True) # Inference net.setInput(blob) d0 = net.forward('output') # Norm pred = normPred(d0[:, 0, :, :]) # Save save_output('test_imgs/sky1.jpg', pred) if __name__ == '__main__': main() 5.3 (c++)使用libtorch方法 // std::string strModelPath = "E:/template/u2net_train.pt"; void bgr_u2net(cv::Mat& image_src, cv::Mat& result, torch::jit::Module& model) { //1.模型已经导入 auto device = torch::Device("cpu"); //2.输入图片,变换到320 cv::Mat image_src1 = image_src.clone(); cv::resize(image_src1, image_src1, cv::Size(320, 320)); cv::cvtColor(image_src1, image_src1, cv::COLOR_BGR2RGB); // 3.图像转换为Tensor torch::Tensor tensor_image_src = torch::from_blob(image_src1.data, { image_src1.rows, image_src1.cols, 3 }, torch::kByte); tensor_image_src = tensor_image_src.permute({ 2,0,1 }); // RGB -> BGR互换 tensor_image_src = tensor_image_src.toType(torch::kFloat); tensor_image_src = tensor_image_src.div(255); tensor_image_src = tensor_image_src.unsqueeze(0); // 拿掉第一个维度 [3, 320, 320] //4.网络前向计算 auto src = tensor_image_src.to(device); auto pred = model.forward({ src }).toTuple()->elements()[0].toTensor(); //模型返回多个结果,用toTuple,其中elements()[i-1]获取第i个返回值 //d1,d2,d3,d4,d5,d6,d7= net(inputs_test) //pred = d1[:,0,:,:] auto res_tensor = (pred * torch::ones_like(src)); res_tensor = normPRED(res_tensor); //是否就是Tensor转换为图像 res_tensor = res_tensor.squeeze(0).detach(); res_tensor = res_tensor.mul(255).clamp(0, 255).to(torch::kU8); //mul函数,表示张量中每个元素乘与一个数,clamp表示夹紧,限制在一个范围内输出 res_tensor = res_tensor.to(torch::kCPU); //5.输出最终结果 cv::Mat resultImg(res_tensor.size(1), res_tensor.size(2), CV_8UC3); std::memcpy((void*)resultImg.data, res_tensor.data_ptr(), sizeof(torch::kU8) * res_tensor.numel()); cv::resize(resultImg, resultImg, cv::Size(image_src.cols, image_src.rows), cv::INTER_LINEAR); result = resultImg.clone(); }5.4 (c++)使用opencv方法 #include "opencv2/dnn.hpp" #include "opencv2/imgproc.hpp" #include "opencv2/highgui.hpp" #include #include "opencv2/objdetect.hpp" using namespace cv; using namespace std; using namespace cv::dnn; int main(int argc, char ** argv) { Net net = readNetFromONNX("E:/template/sky_split.onnx"); if (net.empty()) { printf("read model data failure...\n"); return -1; } // load image data Mat frame = imread("e:/template/sky14.jpg"); Mat blob; blobFromImage(frame, blob, 1.0 / 255.0, Size(320, 320), cv::Scalar(), true); net.setInput(blob); Mat prob = net.forward("output"); Mat slice(cv::Size(prob.size[2], prob.size[3]), CV_32FC1, prob.ptr(0, 0)); normalize(slice, slice, 0, 255, NORM_MINMAX, CV_8U); resize(slice, slice, frame.size()); return 0; }综合考虑后,选择opencv onnx的部署方式 import os import torch from unet import UNet def main(): net = UNet(n_channels=3, n_classes=2, bilinear=True) net.load_state_dict(torch.load("checkpoints/skyseg0113.pth", map_location=torch.device('cpu'))) net.eval() # --------- model 序列化 --------- example = torch.zeros(1, 3, 320, 320) #这里经过实验,最大是 example = torch.zeros(1, 3, 411, 411) torch_script_module = torch.jit.trace(net, example) #torch_script_module.save('unet_empty.pt') torch.onnx.export(net, example, 'checkpoints/skyseg0113.onnx', opset_version=11) print('over') if __name__ == "__main__": main() int main() { //参数和常量准备 Net net = readNetFromONNX("E:/template/skyseg0113.onnx"); if (net.empty()) { printf("read model data failure...\n"); return -1; } // load image data Mat frame = imread("E:\\sandbox/sky4.jpg"); pyrDown(frame, frame); Mat blob; blobFromImage(frame, blob, 1.0 / 255.0, Size(320, 320), cv::Scalar(), true); net.setInput(blob); Mat prob = net.forward("473");//???对于Unet来说,example最大为(411,411),原理上来说,值越大越有利于分割 Mat slice(cv::Size(prob.size[2], prob.size[3]), CV_32FC1, prob.ptr(0, 0)); threshold(slice, slice, 0.1, 1, cv::THRESH_BINARY_INV); normalize(slice, slice, 0, 255, NORM_MINMAX, CV_8U); Mat mask; resize(slice, mask, frame.size());//制作mask }通过这种方法,就能够获得模型推断的模板对象,其中“473”是模型训练过程的层名,由于我们在训练的过程中没有指定,所以按照系统自己的名字给出。 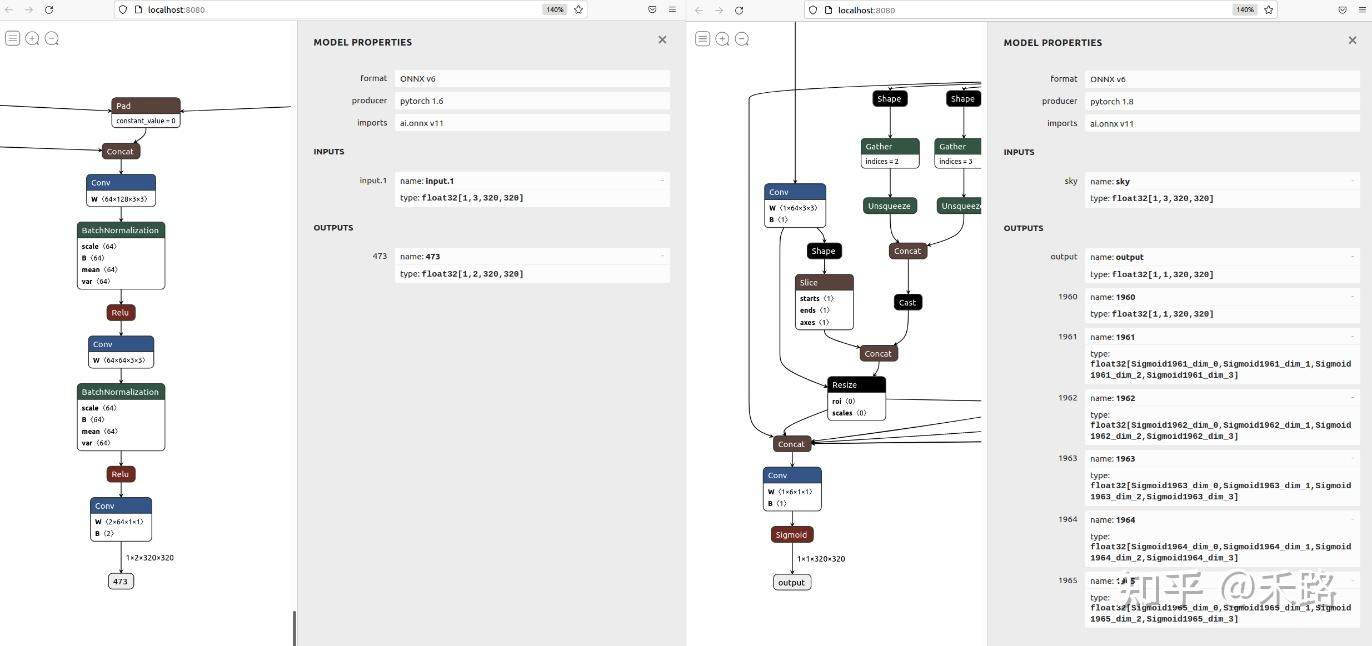 我们可以通过netron的方式查看获得这里的名称。 六、结合SeamlessClone等图像处理方法,实现最终效果 int main() { //参数和常量准备 Net net = readNetFromONNX("E:/template/skyseg0113.onnx"); if (net.empty()) { printf("read model data failure...\n"); return -1; } // load image data Mat frame = imread("E:\\sandbox/sky4.jpg"); pyrDown(frame, frame); Mat blob; blobFromImage(frame, blob, 1.0 / 255.0, Size(320, 320), cv::Scalar(), true); net.setInput(blob); Mat prob = net.forward("473"); Mat slice(cv::Size(prob.size[2], prob.size[3]), CV_32FC1, prob.ptr(0, 0)); threshold(slice, slice, 0.1, 1, cv::THRESH_BINARY_INV); normalize(slice, slice, 0, 255, NORM_MINMAX, CV_8U); Mat mask; resize(slice, mask, frame.size());//制作mask Mat matSrc = frame.clone(); VP maxCountour = FindBigestContour(mask); Rect maxRect = boundingRect(maxCountour); if (maxRect.height == 0 || maxRect.width == 0) maxRect = Rect(0, 0, mask.cols, mask.rows);//特殊情况 ////天空替换 Mat matCloud = imread("E:/template/cloud/cloud1.jpg"); resize(matCloud, matCloud, frame.size()); //直接拷贝 matCloud.copyTo(matSrc, mask); imshow("matSrc", matSrc); //seamless clone matSrc = frame.clone(); Point center = Point((maxRect.x + maxRect.width) / 2, (maxRect.y + maxRect.height) / 2);//中间位置为蓝天的背景位置 Mat normal_clone; Mat mixed_clone; Mat monochrome_clone; seamlessClone(matCloud, matSrc, mask, center, normal_clone, NORMAL_CLONE); seamlessClone(matCloud, matSrc, mask, center, mixed_clone, MIXED_CLONE); seamlessClone(matCloud, matSrc, mask, center, monochrome_clone, MONOCHROME_TRANSFER); imshow("normal_clone", normal_clone); imshow("mixed_clone", mixed_clone); imshow("monochrome_clone", monochrome_clone); waitKey(); return 0; }在调用seamlessClone()的时候报错:  报错原因:可以看seamlessClone源码(opencv/modules/photo/src/seamless_cloning.cpp),在执行seamlessClone的时候,会先求mask内物体的boundingRect,然后会把这个最小框矩形复制到dst上,矩形中心对齐center  这个过程中可能矩形会超出dst的边界范围,就会报上面的roi边界错误。  这里错误的根源应该还是OpenCV 这块的代码有问题,其中roi_s不应该适用BoundingRect进行处理。除了进行修改重新编译,或者直接进行PR解决之外,我们可以采取一些补救的。这里我采取了2手方法来避免异常:一个是在模板制作的过程中,除了获得的最大区域之外,主动地将其他区域涂黑,从而保证BoundingRect能够准确地框选天空区域;二个是在seamlessClone之前,对模板进行异常判断,对可能出现的情况进程处置。 通过添加opencv代码,进行系统联调:  修改后的代码为: int main() { //参数和常量准备 Net net = readNetFromONNX("E:/template/skyseg0113.onnx"); if (net.empty()) { printf("read model data failure...\n"); return -1; } vector vecFilePaths; getFiles("e:/template/sky", vecFilePaths); string strSavePath = "e:/template/sky_change_result"; for (int index = 0;index |
【本文地址】